Note: Post is from YC's Launch BF forum. Represents idea #1 during the batch.
Hey YC! Aryan and Ayush here. We've recently built a tool to help with prompt engineering and wanted to share it for other founders to try.
The Problem
While working on LLM (Large Language Model) applications, the current development cycle looks like this (from PromptLayer):
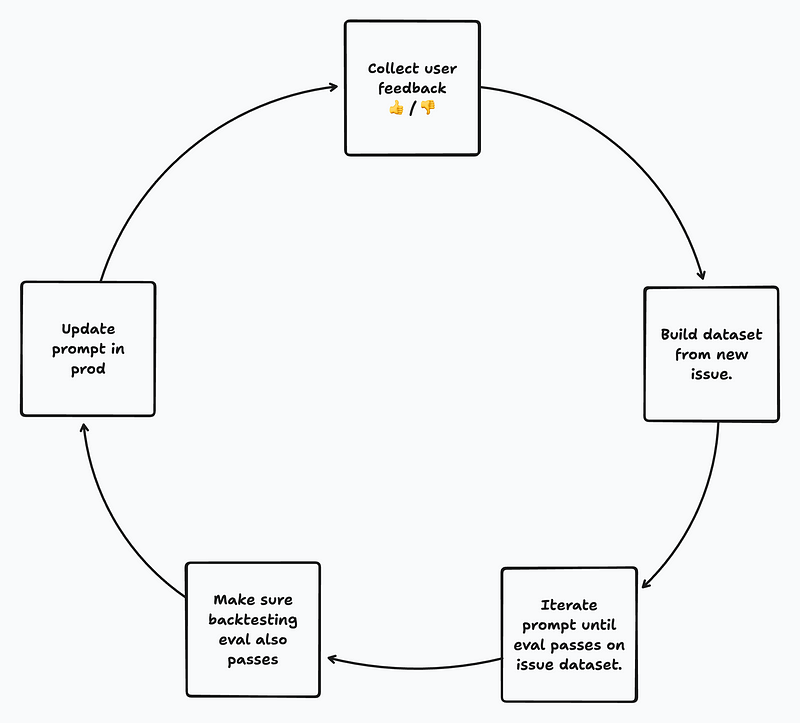
We noticed that the prompt engineering step was taking up a huge chunk of our time. We were constantly manually guessing and tweaking new prompts, trying to figure out what worked best and handling failure cases.
The Solution
We came up with an optimization co-pilot to speed up this process while still enabling human-in-the-loop feedback.
First, define your prompt and evaluation rules in natural language. Then, we score your model across your data.

In this version, our accuracy was decent (around 70%), but there were still mistakes. By providing feedback to the optimizer, the tool will generate a new, more structured and detailed prompt, including a few explicit examples to guide the model on how to act properly.
Results
With the updated prompt, we saw an improvement in both accuracy and professionalism.
No more hallucinations!
You can try an example of this at: demo.kisho.app
What's Next?
We have a few improvements in mind to make this even more useful, like:
- Autonomous optimization (testing thousands of prompts for you automatically)
- A/B testing (giving real data on how prompts compare in production)
If you have use cases that could benefit from this, we’d love to hear from you: aryan@kisho.app